library(randomForest)
# Run the model
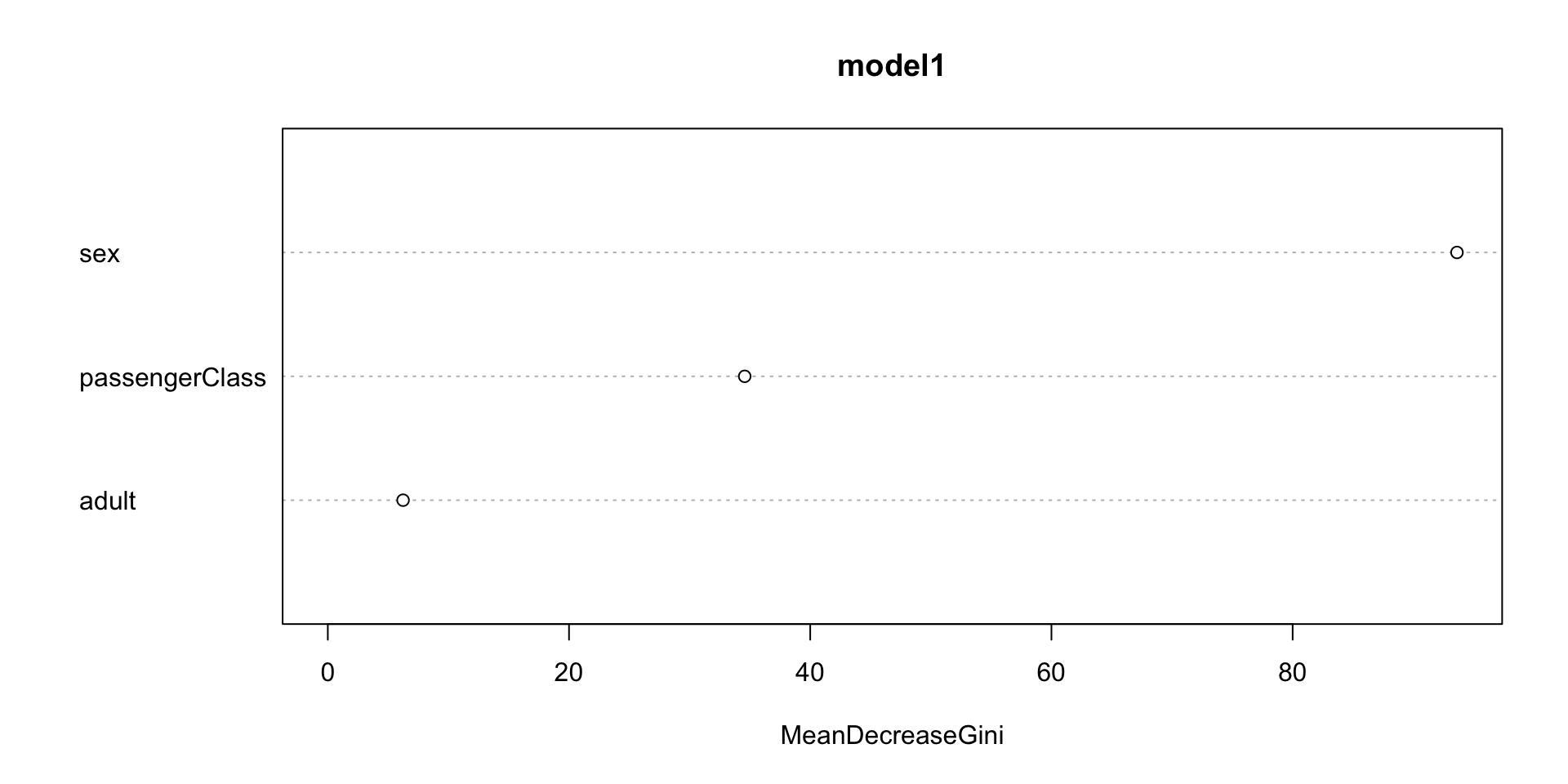
model1 = randomForest(survived ~ adult + sex + passengerClass, data = titanic_age)
# Show details on the model
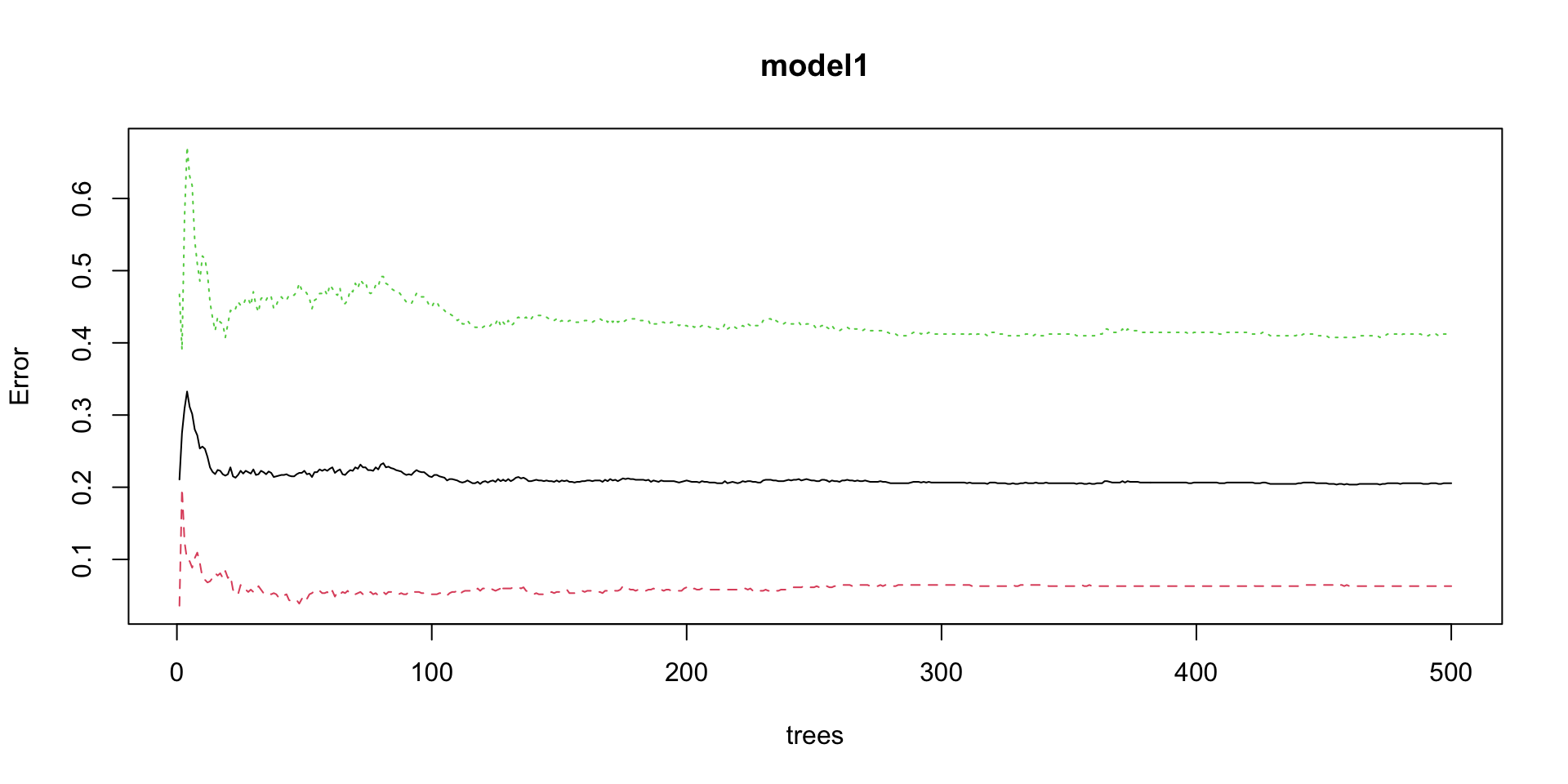
print(model1)
Call:
randomForest(formula = survived ~ adult + sex + passengerClass, data = titanic_age)
Type of random forest: classification
Number of trees: 500
No. of variables tried at each split: 1
OOB estimate of error rate: 20.55%
Confusion matrix:
no yes class.error
no 580 39 0.06300485
yes 176 251 0.41217799