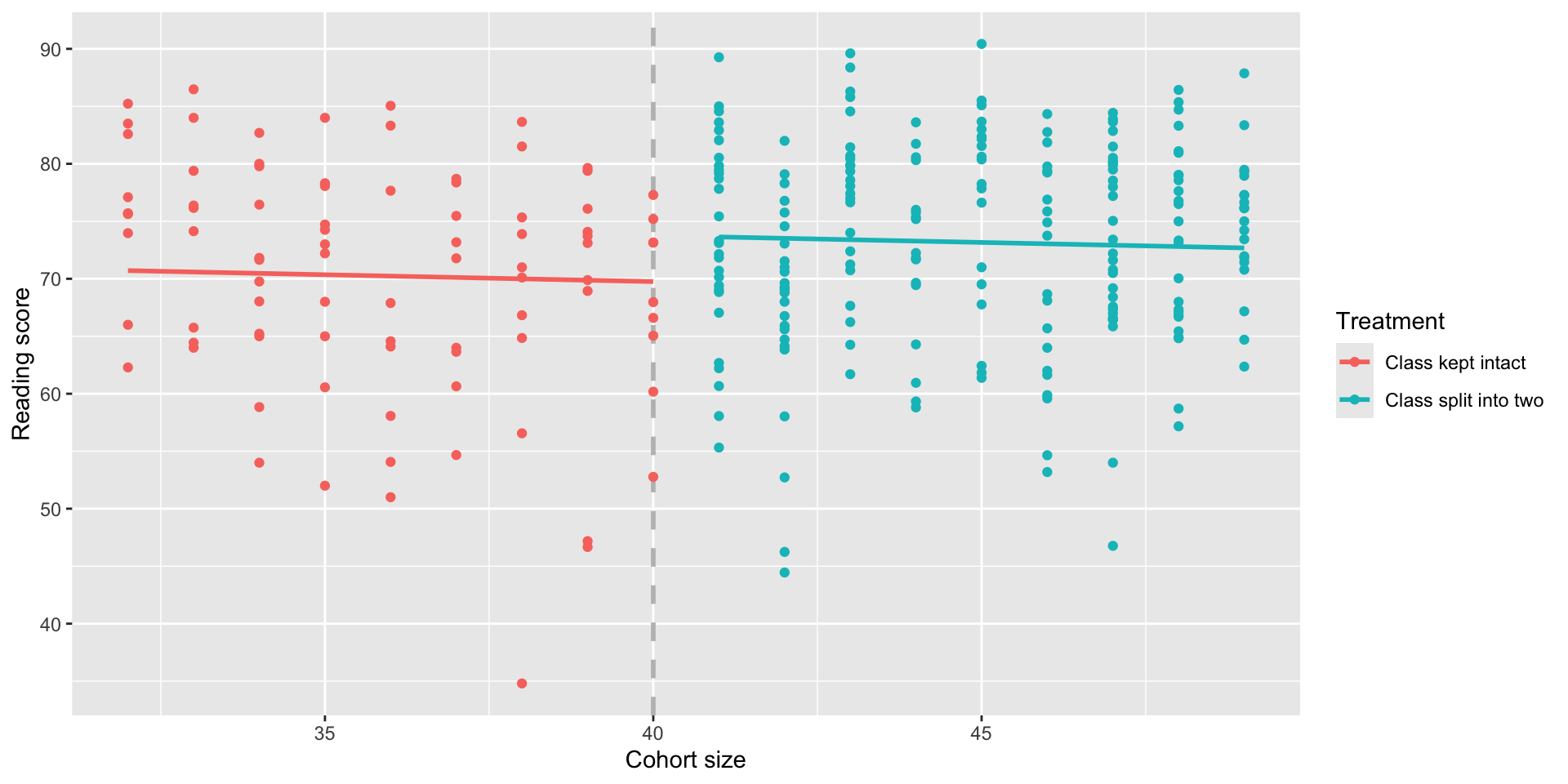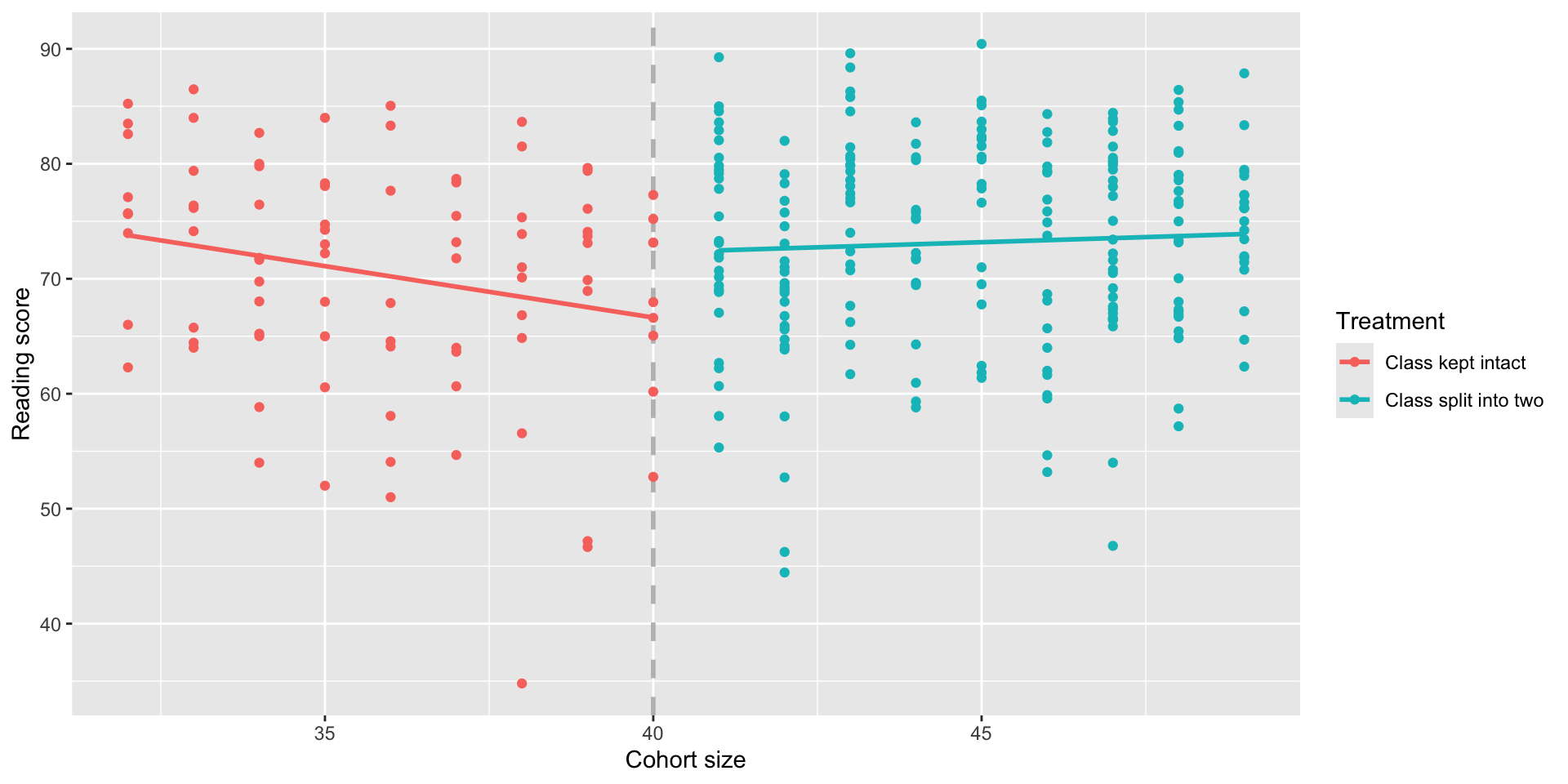
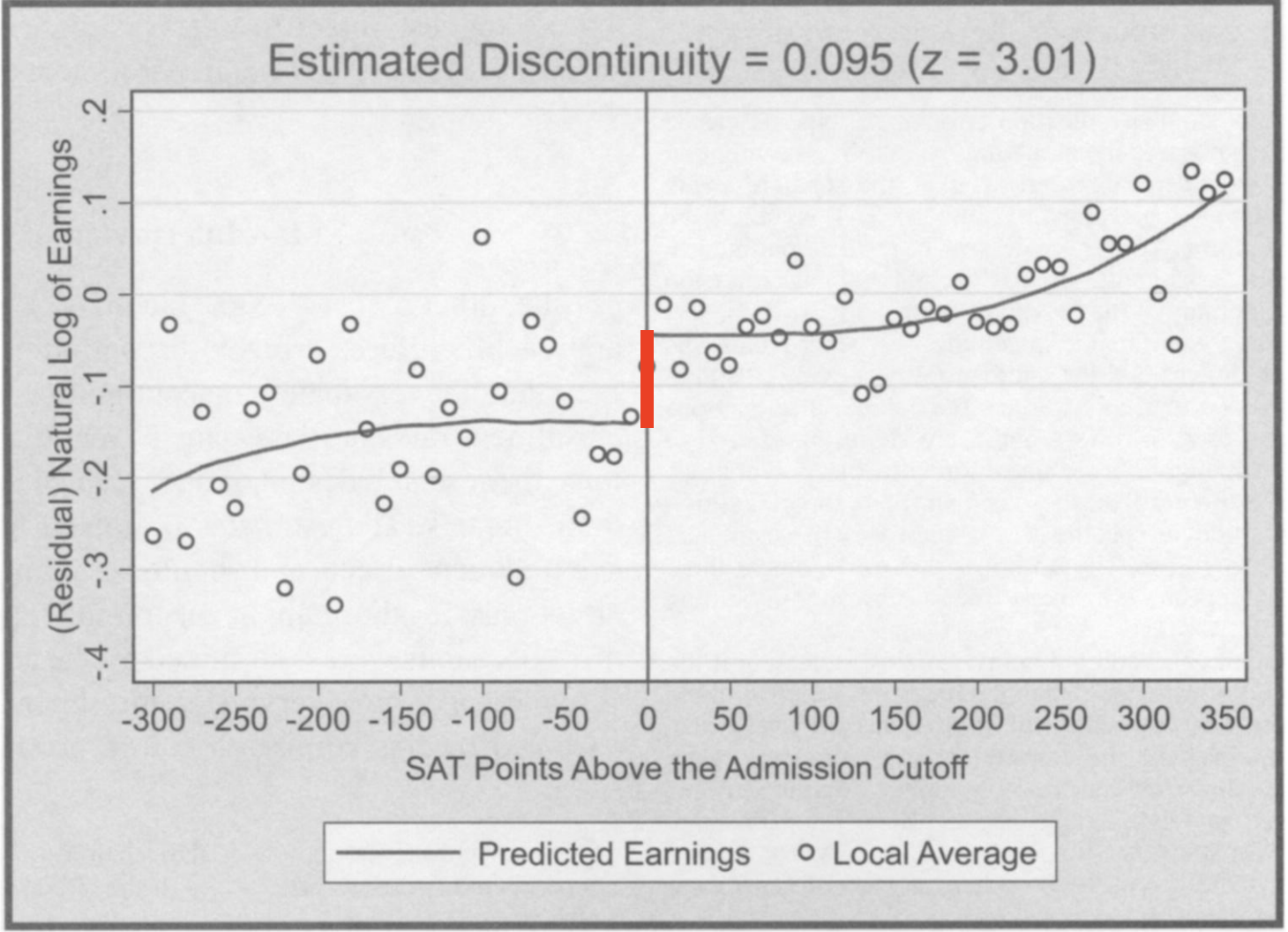
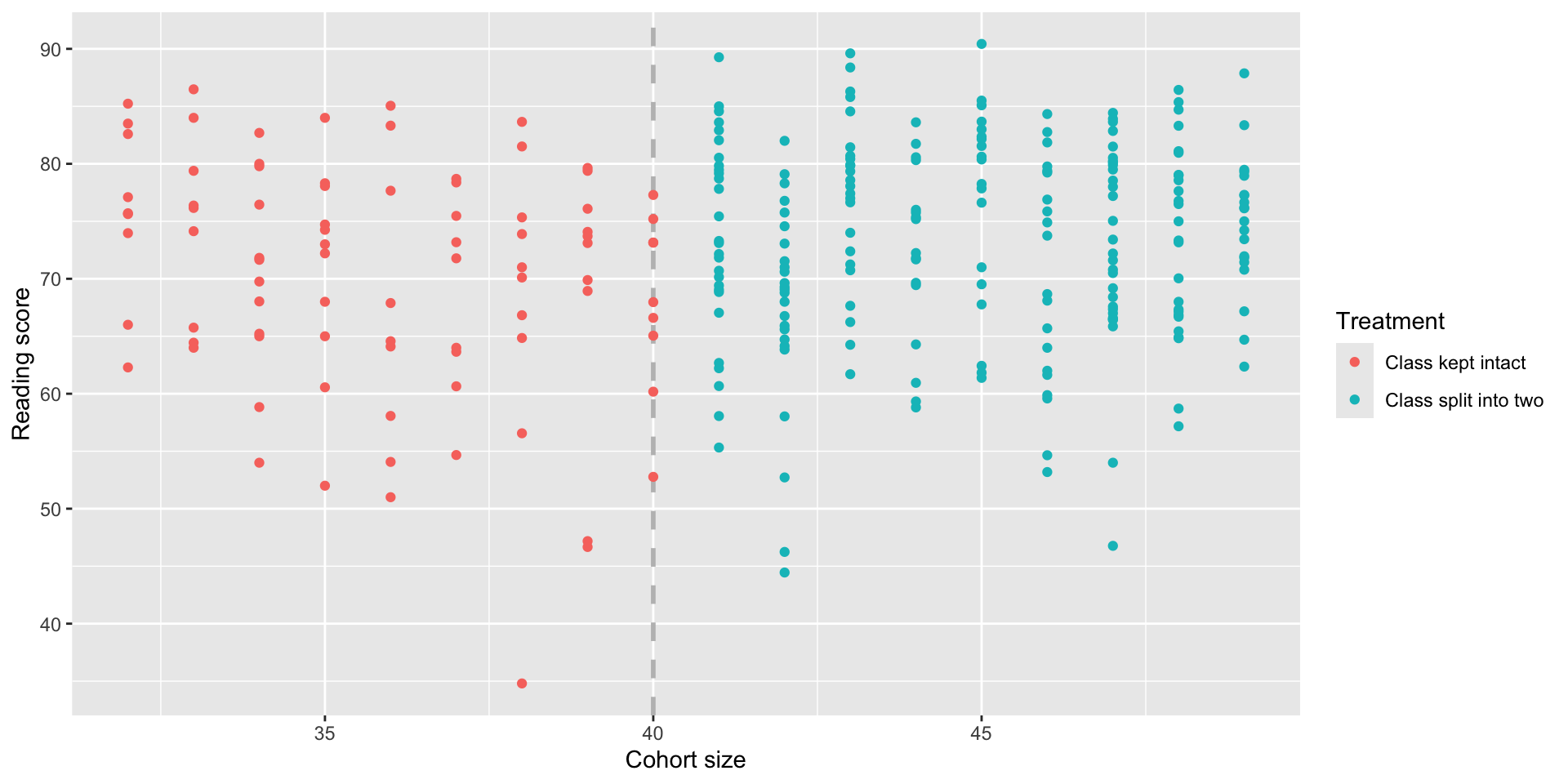
school <- school %>%
mutate(
treatment = ifelse(cohort.size > 40, 1, 0),
selection = cohort.size - 40
)
rdd1 <- lm(read ~ selection + treatment, data = school)
summary(rdd1)
Call:
lm(formula = read ~ selection + treatment, data = school)
Residuals:
Min 1Q Median 3Q Max
-35.195 -5.572 1.537 6.617 17.269
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 69.7556 1.2697 54.939 <0.0000000000000002 ***
selection -0.1195 0.2020 -0.592 0.5545
treatment 4.0031 2.1511 1.861 0.0638 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 9.135 on 294 degrees of freedom
Multiple R-squared: 0.02237, Adjusted R-squared: 0.01572
F-statistic: 3.363 on 2 and 294 DF, p-value: 0.03596